

High Performance Computing Division
Toward the Development of Accessible HPC Infrastructure
The High Performance Computing Division at the Information Technology Center is researching what kinds of environment and operations can improve supercomputers efficiency and ease of use. We are also conducting research in parallel and distributed computing, focusing on such fields as auto-tuning, GPU computing, big data processing, large-scale machine learning, and numerical simulation of fluid flows, structure, and seismic waves.
 |
 |
 |
 |
 |
Main components of Supercomputer "Flow"
Development of a Computer Language for Auto-tuning
To maximize performance in advanced CPUs on supercomputers for numerical simulations of scientific and technology computations, highly knowledge between computer architectures and numerical algorithms is required. It is also time-consuming work that we need several trials to optimize target codes. To reduce these “costs” of tuning, auto-tuning (AT) technologies, which enable us to obtain high performance software automatically in several computer environments, are spotlighted as an upcoming technology. In this research, we develop AT methodology and a computer language for AT that can add AT facility to arbitrary codes, named ppOpen-AT, with advanced supercomputers in operation.
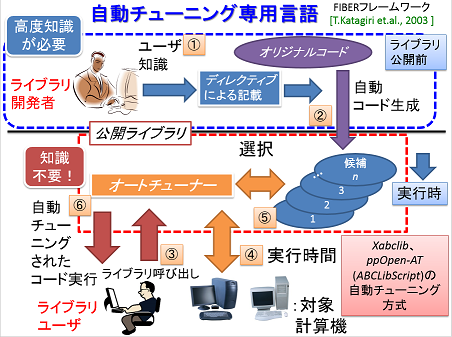
A Process Flow by Utilizing a Computer Language for AT.
High performance computing using GPU
Graphics Processing Unit (GPU) is originally developed for graphics (imaging) processing, but it is used as a high performance computing hardware because it can execute many calculations in parallel and obtain high performance. Today, GPU is also used to accelerate Machine Learning and AI processing.
However, GPU can't accelerate any kind of calculations. GPU is good at simple and highly parallel calculations, but not good at complex (having many conditional branches) calculations.
In this research, we develop fast computation algorithm and implementation for GPU, and accelerate applications on GPU.
High Performance Computing of Structural Analysis
For disaster prevention and mitigation, it is important to improve accuracy and computational performance of numerical simulation of large artifacts. To solve these issues effectively, we are proceeding with research on iterative methods for large sparse linear systems on a distributed memory multiprocessor. A method to solve wave equations of arbitrarily inhomogeneous and anisotropic medium in the frequency domain was recently developed and its numerical validation is ongoing. The study is expected to open a new approach to structure estimations of Earth’s interior and/or large-body engineering structures.
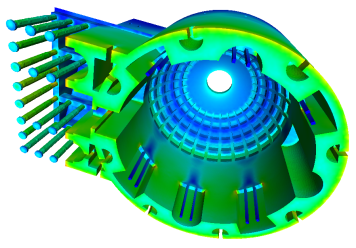
An elastostatic analysis of a Patheon model
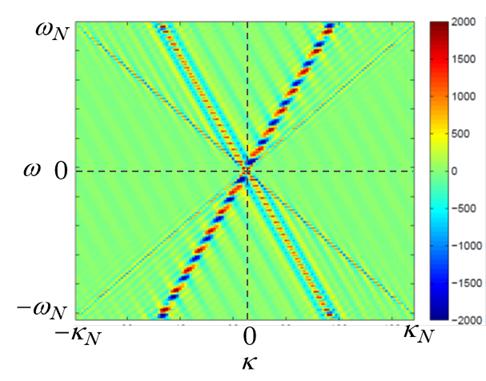
A calculation of elastic wave field